Statystyczna Eksploracja Danych
LABORATORIUM 8
MASZYNY WEKTORÓW NOŚNYCH
Maszyny wektorów nośnych (podpierających) [ang. support vector machines] są dość współczesną (z last 90-tych XX w.) metodą uczenia pod nadzorem. Ich podstawową cechą jest nowe spojrzenie na problem hiperpłaszczyzny rozdzielającej: zadanie polega na znalezieniu jak największego możliwego marginesu, rodzialającego punkty należące do różnych klas. Same hiperpłaszczyzny marginesów muszą przechodzić przez konkertne elementy próby uczącej i są nazwany właśnie wektorami podpierającymi. Problem został omówiony szerzej naWykładzie 6
Matematycznie oznacza to, że w przypadku próby uczącej o \(n\) obserwacjach mamy do czynienia z zagadnieniem funkcji Lagrange'a.
maksymalizowanej przy ograniczeniach
W powyższych wzorach \(y_i=\{-1;1\}\) jest klasą wektora obserwacji \(\mathbf{x}_i\) natomiast \(\mathbf{x}_i \cdot \mathbf{x}_j\) jest iloczynem skalarnym. Współczynniki \(\alpha_i\) dają wartości niezerowe jedynie dla wektorów nośnych. Dzięki temu możliwe jest wyznaczenie wektora określającego hiperpłaszczyznę rozdzielającą
a wyraz wolny jest równy
gdzie \(\mathbf{x}^{*}_{1}\) i \(\mathbf{x}^{*}_{-1}\) to punkty, przez które przechodzą wektory nośne.
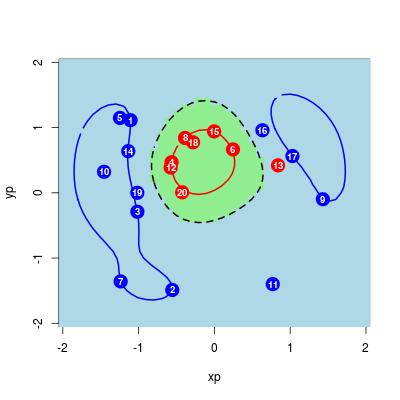
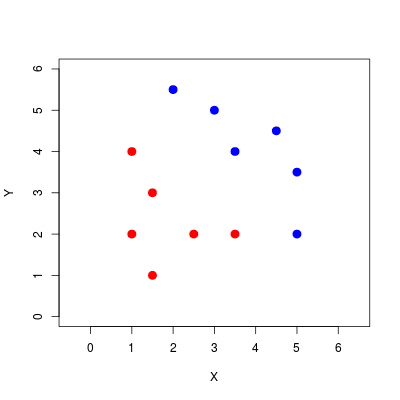
Jako ilustrację wykorzystamy prosty przykład z 12 obserwacjami z dwóch klas.
Rysunek 9.1
Użyjemy funkcji svm() z biblioteki e1071, przy czym ponieważ funkcja jest dość ogólna i obsługuje różne przypadki, musimy podać dość konkretne opcje: wybrać klasyfikację, ustawić wysoki koszt, dać liniowe jądro, a także nie pozwolic na przeskalowywanie.
x y.1
6 3.5 2.0
7 2.0 5.5
11 5.0 2.0
# Wartości współczynników alfa
print(data.svm$coefs)
[,1]
[1,] 1.5416840
[2,] -0.3264949
[3,] -1.2151892
Jak widać, jedynie trzy punkty stanowią SV (supporting vectors - wektory nośne), przy czym wartości współczynników \(\alpha\) kodują od razu klasę poprzez umieszczenie znaku - lub +..
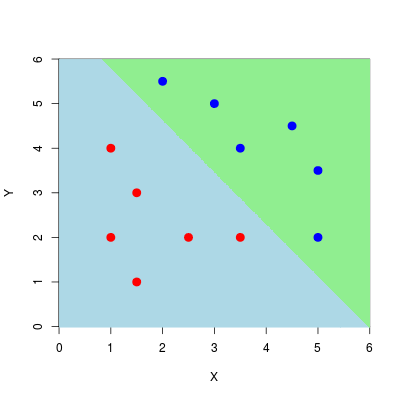
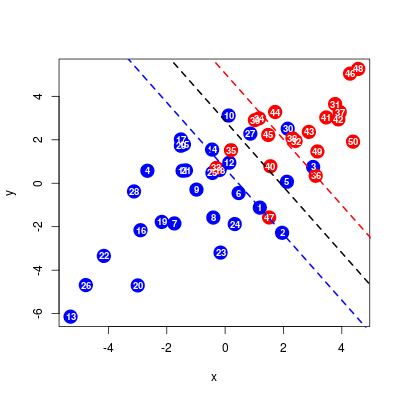
Następnym krokiem jest wizualizacja działania algorytmu. W tym celu rozepniemy siatkę na współrzędnych i dokonamy przewidywania klas na tak skonstruowanych punktach za pomocą funkcji predict(), po czym wyniki wyświetlimy za pomocą funkcji image(), dodając oryginalne punkty.
Rysunek 9.2
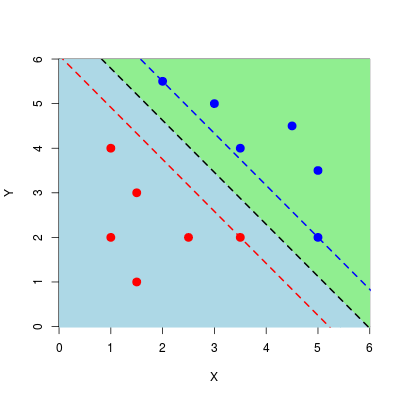
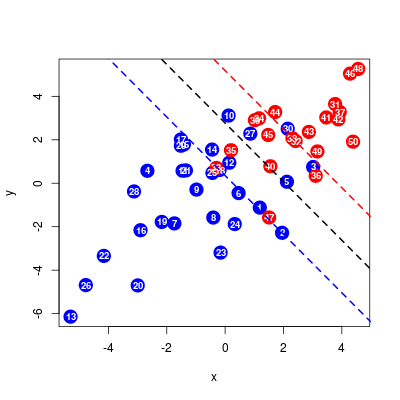
Na koniec wyznaczymy wektor \(\mathbf{w}\) i dzięki niemu naniesiemy na wykres hiperpłaszczyznę rodzielająca oraz hiperpłaszczyzny marginesów.
Rysunek 9.3
BRAK SEPAROWALNOŚCI
Oczywiście, idealna separowalność klas jest pożądana, lecz nie zawsze możliwa do osiągnięcia. W takich wypadkach kluczową rolę odgrywa wartość \(C\), która określa "karę" za przekroczenie granicy marginesów. W zapisie matematycznym dalej dokonujemy maksymalizacji funkcji Lagrange'a
przy czym ograniczenie są teraz w postaci
x y.1
1 1.1887760 -1.12149780 5.125037
2 1.9523878 -2.28057082 3.667998
3 3.0173246 0.74834428 10.000000
5 2.1199128 0.06827946 10.000000
10 0.1188442 3.11589903 10.000000
12 0.1436874 0.94538990 10.000000
14 -0.4461424 1.54912322 10.000000
27 0.8645302 2.28290458 10.000000
30 2.1459450 2.50867866 10.000000
33 -0.2963546 0.70566865 -10.000000
34 1.1638198 2.98878072 -10.000000
35 0.2020300 1.52111496 -10.000000
36 3.1049032 0.34285937 -8.793036
39 1.0211324 2.90574104 -10.000000
40 1.5512155 0.78304568 -10.000000
45 1.4777660 2.22239838 -10.000000
47 1.5091429 -1.57514470 -10.000000
# Wyznaczenie wektora w
w <- t(data.svm$SV) %*% data.svm$coefs
b <- data.svm$rho
xx <- -5:5
# Hiperpłaszczyzna rodzielająca
lines(xx, -w[1] / w[2] * xx + b / w[2], lty = 2, lwd = 2)
# Hiperpłaszczyzny marginesów
lines(xx, -w[1] / w[2] * xx + (b + 1) / w[2], lty = 2, lwd = 2, col = "blue")
lines(xx, -w[1] / w[2] * xx + (b - 1) / w[2], lty = 2, lwd = 2, col = "red")Rysunek 9.4
Rzecz jasna, stałą \(C\) musimy dobrać sami, np. na podstawie próby testowej, kroswalidacji albo oceny prawdopodobieństwa błędnej klasyfikacji. Biorąc pod uwagę losowy charakter danych, zaproponowanie małej wartości \(C\) umożliwia przeciwdziałanie nadmiernemu dopasowaniu do próby uczącej. Poniżej wektory nośne oraz rysunek dla \(C=0.5\)
1 1.1887760 -1.12149780 0.50000000 2 1.9523878 -2.28057082 0.08643563 3 3.0173246 0.74834428 0.50000000 5 2.1199128 0.06827946 0.50000000 10 0.1188442 3.11589903 0.50000000 12 0.1436874 0.94538990 0.50000000 14 -0.4461424 1.54912322 0.50000000 18 -0.1897206 0.60902497 0.09466662 27 0.8645302 2.28290458 0.50000000 30 2.1459450 2.50867866 0.50000000 33 -0.2963546 0.70566865 -0.50000000 34 1.1638198 2.98878072 -0.50000000 35 0.2020300 1.52111496 -0.50000000 36 3.1049032 0.34285937 -0.50000000 38 2.3091887 2.07341323 -0.18110224 39 1.0211324 2.90574104 -0.50000000 40 1.5512155 0.78304568 -0.50000000 45 1.4777660 2.22239838 -0.50000000 47 1.5091429 -1.57514470 -0.50000000
Rysunek 9.5
JĄDRA NIELINIOWE
Zależność od przestrzeni obserwacji \(\mathbb{R}^p\) przejawia się jedynie przez obliczanie iloczynu skalarnego. Dlaczego jest to takie istotne? Otóż wszystkie takie obliczenia dotyczą jedynie iloczynu skalarnego, a nie przekształconych obserwacji, a dokonanie nieliniowej transformacji często umożlwia dokładną klasyfikację. W praktyce takie podejście sprowadza się do zamiany iloczynu skalarnego w funkcji Lagrange'a na opowiednie jądro \(K\)
występuje wyjątkowo często.
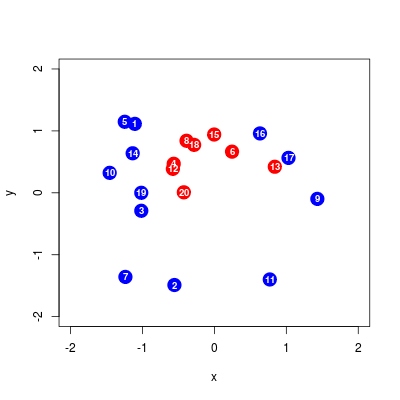
Poniżej przykładowy zbiór danych.
x y class alfa
9 1.431222351 -9.802896e-02 klasa2 2.043324
11 0.770234668 -1.399431e+00 klasa2 0.674040
13 0.839799972 4.204576e-01 klasa1 -37.949851
15 -0.003407008 9.411202e-01 klasa1 -2.467940
16 0.633555739 9.585604e-01 klasa2 6.153747
17 1.030213225 5.635880e-01 klasa2 29.943637
19 -1.016943997 1.254212e-05 klasa2 1.603042
Rysunek 9.6
Rysunek 9.7
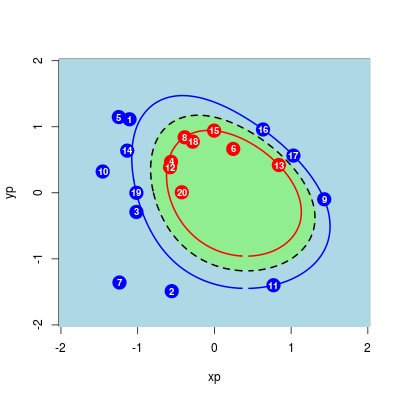
Zmiany parametrów mogą prowadzić do dziwnych efektów - poniżej \(C=1\) i \(\gamma=2\).
Rysunek 9.8