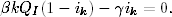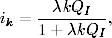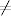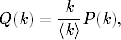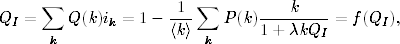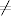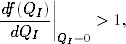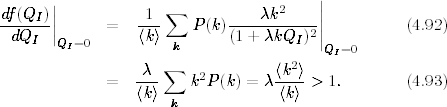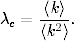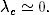Wielkie epidemie, takie jak epidemia dżumy, zwanej potocznie czarną śmiercią,
która spustoszyła czternastowieczną Europę, zabijając trzecią część jej
mieszkańców1,
lub pandemia2
grypy hiszpanki, na którą w czasie pierwszej wojny światowej zmarło
przeszło 100 mln ludzi na całym świecie, zdarzały się dosyć często
w historii naszej cywilizacj. Sukcesy medycyny sprawiły
jednak, że dzisiaj z dystansem traktujemy prasowe doniesienia na temat
nowych szczepów grypy czy też nieznanych dotychczas odzwierzęcych
wirusów3.
Wierzymy, że współczesna, stojąca na wysokim poziomie służba zdrowia nas
ochroni, a odpowiednie środki finansowe, masowe szczepienia, w wyjątkowych
przypadkach zaś po prostu odosobnienie i kontrola chorych osobników rozwiąże
resztę problemów. W tym podrozdziale pokażemy, że taki optymizm jest
bezpodstawny. Prawda jest taka, że mamy się czego obawiać. Bezskalowa
struktura sieci społecznych sprzyja bowiem rozprzestrzenianiu się wirusów. Z
tego właśnie powodu w walce z różnymi chorobami zakaźnymi niemal zupełnie
nie mamy szans na wygraną. To dlatego choroby takie jak różyczka, grypa,
gruźlica4,
a nawet AIDS są ciągle, mimo zakrojonej na szeroką skalę profilaktyki
zdrowotnej, tak bardzo powszechne.
Aby zrozumieć fenomen rozprzestrzeniania się epidemii w sieciach złożonych
prześledźmy początkowy etap rozprzestrzeniania się wirusa HIV w Stanach
Zjednoczonych na początku lat 80. ubiegłego wieku. Pierwsze przypadki zachorowań
na AIDS5
odnotowano tam w maju 1981 roku. Wszyscy chorzy byli młodymi gejami.
Specjaliści z amerykańskiego Centrum Kontroli i Prewencji Zakażeń
(CDC)6
rozpoczęli wtedy dokładne śledztwo, przeprowadzając wywiady z czterdziestoma
pierwszymi pacjentami wykazującymi objawy tej nowej, nieznanej dotąd choroby.
Uzyskane informacje pozwoliły odtworzyć mapę kontaktów seksualnych tych
osób i ponad wszelką wątpliwość stwierdzić, że choroba była przenoszona drogą
płciową. Do analizy zebranych danych zaproszono specjalistów w dziedzinie
badania sieci społecznych. Zastosowane przez nich metody analizy układów
sieciowych pozwoliły z gęstej sieci kontaktów seksualnych wyłonić tzw.
Pacjenta Zero, któremu przypisano kluczową rolę w zapoczątkowaniu epidemii.
Ośmiu, spośród jego partnerów, znalazło się w grupie czterdziestu zarażonych,
którzy pomogli specjalistom z CDC w odtworzeniu pierwszego etapu
epidemii.
Kim był Pacjent Zero? Nazywał się Gaetan Dugas (1953–1984) i pracował
jako steward w kanadyjskich liniach lotniczych. Był gejem, który wykazywał
niezwykłą aktywność seksualną. Z jego późniejszych wypowiedzi wynikało, że
miewał średnio 250 partnerów rocznie. Specjaliści szacują, że zanim zmarł na
AIDS, mógł mieć do 2500 partnerów. Co prawda nie ma pewności, czy to on
przeniósł tę chorobę z Afryki na kontynent amerykański. Pewna jest natomiast
jego kluczowa rola w początkowym etapie rozprzestrzeniania tej epidemii na
terenie Stanów Zjednoczonych. Mówiąc językiem analityków sieci, był on hubem
w bezskalowej sieci dyfuzji czynnika zarażającego. Sieci kontaktów
seksualnych należą bowiem do klasy sieci bezskalowych o potęgowym rozkładzie
stopni wierzchołków. Potwierdzają to liczne badania, na przykład opublikowane
w 2000 roku wyniki ankiet na temat postaw i skłonności seksualnych
Brytyjczyków.
Ankiety te przeprowadzone z udziałem kilkunastu tysięcy kobiet i mężczyzn,
pokazały, że większość z respondentów (zarówno kobiet, jak i mężczyzn)
miała w ciągu ostatniego roku od jednego do dziesięciu partnerów.
Znaczenie mniejsza część chwaliła się kilkudziesięcioma partnerami.
Kilku rekordzistów (pokroju Gaetana Dugasa) przyznało się jednak do
uprawiania seksu z kilkuset osobami. Uzyskane histogramy liczby partnerów
seksualnych7
miały postać praw potęgowych o wykładnikach charakterystycznych α z przedziału (2,3)
(rysunek 2H)8.
Z tych badań wynika jeden bardzo ważny wniosek: mówienie o średniej
aktywności seksualnej ludzi nie ma sensu. Zachowania seksualne nie są opisane
rozkładem normalnym, nie mają naturalnej skali, są bezskalowe. Klasyczne
podejście do modelowania dynamiki chorób przenoszonych drogą płciową,
polegające na pozornie realistycznym założeniu, że wszyscy ludzie mają dobrze
określoną średnią liczbę partnerów, przy czym osoby wstrzemięźliwe i
nadaktywne seksualnie nie odgrywają w układzie znaczącej roli, jest po prostu
błędne i prowadzi do poważnych przekłamań.
Aby dostrzec skalę problemu, wyprzedzimy nieco rozważania teoretyczne
zamieszczone w dalszej części tego podrozdziału i omówmy podstawowe wnioski
klasycznych modeli rozprzestrzeniania się epidemii. Otóż z tych
tradycyjnych modeli, opartych na rozkładach normalnych, wynika, że to, czy
dojdzie do epidemii, czy do wygaśnięcia choroby, zależy przede wszystkim od
aktywności czynnika infekcyjnego. Według tych modeli, do zaistnienia
epidemii potrzebny jest pewien próg zaraźliwości, który w naszych
dalszych rozważaniach będziemy nazywali krytyczną wartością tempa
rozprzestrzeniania sie epidemii. Podstawowym wnioskiem płynącym z
tych modeli jest to, że tempo epidemii można obniżyć, stosując masowe
działania profilaktyczne (np. szczepienia), mające zwiększyć ogólnie
rozumianą, średnią odporność całej populacji. Podobne działania są wciąż
podejmowane w wypadku większości chorób zakaźnych. Doświadczenie
pokazuje jednak, że taka taktyka jest nieskuteczna. Dlaczego? Otóż
dlatego, bo w sieciach bezskalowych próg zaraźliwości jest równy zeru. Rola
Pacjenta Zero w epidemii wirusa HIV w Stanach Zjednoczonych wskazuje na
specyfikę rozprzestrzeniania się chorób zakaźnych w sieciach bezskalowych.
Wirus, przez wiele lat może egzystować gdzieś na peryferiach populacji,
przez nikogo nie zauważony. Do wybuchu epidemii wystarczy jednak,
by nosicielem wirusa stał się jeden z bardziej aktywnych osobników –
hub.
Powyższy wywód pokazuje, że w sieciach bezskalowych stosowane
dotychczas strategie ochrony zdrowia polegające na masowej immunizacji
(np. przez szczepienia ochronne), doraźnej eliminacji (przez leczenie
pojedynczych osobników) i kontroli (przez np. system zwolnień lekarskich)
chorych osobników są niewłaściwe. W takich sieciach jedynym skutecznym
sposobem walki z epidemią jest tropienie i eliminacja kluczowychwęzłów.
Wirusy w sieciach komputerowych
Philip Ball9
w swojej książce Masa krytyczna napisał: wirusy elektroniczne mogą sparaliżowaćInternet, podobnie jak wirusy biologiczne przykuć nas do łóżka. Trudno się nie
zgodzić z tym obrazowym porównaniem. Bo chociaż, jak pisze Ball w swojej
książce, wirusy komputerowe nie są (na razie) zabójcze, ale stanowią kosztownąudrękę. Mogą spustoszyć komercyjne zasoby sieciowe i przysporzyć wielu
kłopotów indywidualnym użytkownikom.
Do historii przeszły już takie epidemie w sieciach komputerowych, jak ta, którą wywołał
robak 10
o nazwie Slummer. W styczniu 2003 zainfekował on serwery Microsoft SQL na
całym świecie. Powszechnie wiadomo, że był on także odpowiedzialny za
unieruchomienie praktycznie całej sieci komputerowej w Korei Południowej.
Mało kto wie jednak o tym, że przeniknął również do sieci elektrowni atomowej
Davis-Besse w stanie Ohio w Stanach Zjednoczonych, powodując wyłączenie na
kilka godzin ważnych systemów monitorujących jej pracę. Ten ostatni przykład
wydatnie pokazuje, że w przyszłości, złośliwe oprogramowanie komputerowe
może być wykorzystywane przez cyberterrorystów.
Przykłady epidemii wirusów i robaków w sieciach komputerowych można by
wyliczać jeszcze długo. Zanim jednak zakończymy dyskusję
poświęconą wirusom komputerowym chcielibyśmy jeszcze zwrócić uwagę na to,
że mechanizmy rozprzestrzeniania się złośliwego oprogramowania w
sieciach komputerowych są bardzo podobne do tych, z którymi mamy do
czynienia podczas rozprzestrzeniania się chorób zakaźnych w sieciach
społecznych. Już wielokrotnie w tej książce mówiliśmy o tym, że Internet,
podobnie jak większość sieci społecznych, jest siecią bezskalową. Próg
zaraźliwości Internetu jest zatem bliski zeru. Z tego właśnie powodu, mimo że
oprogramowanie antywirusowe jest dostępne już w kilka godzin po odnotowaniu
pojawienia się groźnego wirusa, różne wirusy i robaki komputerowe, w stanie
endemicznym11,
mogą przeżyć w Internecie nawet do kilkunasty
miesięcy12
(rysunek 4.11).
Rys. 4.11:
Prawdopodobieństwo Ps(t) przeżycia wirusów w Internecie w
funkcji czasu t, który upłynął od momentu ich powstania. Każdy punkt na
tym wykresie reprezentuje czas życia jednego z 814 wirusów, które pojawiły
się i zostały unieszkodliwione w okresie: od lutego 1996 do marca 2000 (50
miesięcy). Jak pokazano na rysunku, prawdopodobieństwo przeżycia wirusa
jest opisane rozkładem wykładniczym Ps(t) ~ e−t∕τ o charakterystycznym
czasie zaniku τ zależnym od mechanizmu rozprzestrzeniania się wirusa. W
wypadku wirusów sektora startowego i makro ten charakterystyczny czas
zaniku jest równy τ = 14 miesięcy, dla wirusów plikowych wynosi natomiast
τ = 7 miesięcy.
Modelowanie epidemii
Pierwszy znany opis matematyczny procesu rozprzestrzeniania się epidemii
został wykonany przez Bernoullego w 1760 roku. Opis ten był oparty na
równaniach różniczkowych, których współczynniki charakteryzowały własności
choroby zakaźnej. I chociaż od czasów Bernoullego nauki medyczne bardzo się
rozwinęły13,
podobnie zresztą jak różne matematyczne metody opisu procesów
rozprzestrzeniania się, do dzisiejszego dnia równania różniczkowe stanowią
podstawowe narzędzie badawcze do modelowania dynamiki chorób zakaźnych.
Takim ponadczasowym modelem rozprzestrzeniania się epidemii, opartym na
układzie równań różniczkowych zwyczajnych i mającym ogromny wpływ na
rozwój modelowania matematycznego w tym zakresie był model SIR
zaproponowany przez Kermacka i McKendricka na początku ubiegłego
wieku.
W tym klasycznym, ale nie tracącym aktualności modelu zakłada się, że
liczebność badanej populacji nie zmienia się w czasie. Rozprzestrzenianie się
epidemii polega na tym, że osoby chore zarażają zdrowe, przekazując tym
ostatnim patogen, jakim jest wirus lub bakteria. Zakłada się również, że chore
osobniki po wyzdrowieniu stają się odporne, tzn. nie są podatne na kolejne
infekcje wywołane tym samym patogenem. Jednostki, które zmarły w
wyniku choroby, również uważa się za odporne i w dalszym ciągu się je
zlicza. Przebieg choroby w tym modelu prowadzi do podziału rozważanej
populacji na trzy grupy osobników (pierwsze litery angielskich nazw
osobników należących do każdej z tych grup tworzą nazwę modelu –
SIR):
podatnych (ang. susceptible), czyli takich, którzy mogą zachorować,
zainfekowanych (ang. infected), którzy chorują i roznoszą infekcję,
ozdrowiałych (ang. recovered), do tej grupy zaliczamy osobników,
którzy wyzdrowieli i nabyli odporność (lub takich, którzy umarli na
skutek przebytej choroby, ang. removed).
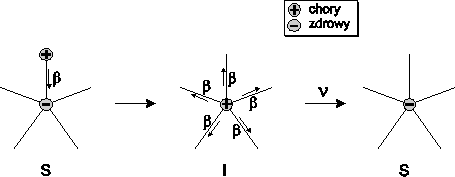
Przejścia między wymienionymi grupami opisuje schemat:
(4.62)
który reprezentuje również sekwencje zmiany stanów opisujących stan
zdrowia osobników należących do badanej populacji. Osobnik zdrowy
(podatny, S) mający kontakt z osobnikiem chorym (zainfekowanym, I), z
pewnym prawdopodobieństwem, zależnym m.in. od rodzaju patogenu, może
zostać zarażony wirusem. Po pewnym czasie jednak, taki chory osobnik
zdrowieje (zmienienia stan na R), uzyskując przy tym odporność na daną
chorobę.
Przyjmując, że wielkości (liczebności) poszczególnych grup osobników:
podatnych, zainfekowanych i ozdrowiałych są odpowiednio równe: S, I oraz R,
układ równań, który opisuje rozprzestrzenianie się epidemii w czasie można
zapisać w postaci
gdzie r,a > 0. Pierwsze z tych równań (4.63
) opisuje tempo zmiany liczebności
grupy osobników zdrowych, podatnych na infekcję. Ponieważ to chorzy zarażają
zdrowych, tempo to musi być proporcjonalne do liczby przenoszących infekcję I,
ale również do liczby tych, którzy są na infekcję podatni S. Z tego powodu
prawa strona równania (4.63
) jest, z dokładnością do znaku, taka sama jak
pierwszy wyraz po prawej stronie równania (4.64
). Podobnie tempo przyrostu
osobników ozdrowiałych (4.65
) jest proporcjonalne do liczby osobników
zainfekowanych. Prawa strona równania (4.65
) jest taka sama, jak wzięty ze
znakiem minus, drugi wyraz występujący po prawej stronie równania (4.64
). Nie
może być inaczej. Te dwa wyrazy reprezentują bowiem tych samych
osobników, którzy po wyzdrowieniu opuszczają grupę zainfekowanych,
zwiększając tym samym liczebność ostatniej grupy, do której należą jednostki
uodpornione.
Model rozprzestrzeniania się epidemii SIR, którego główne założenia zostały
ujęte w postaci układu równań (4.63)–(4.65), można uogólnić na wiele
sposobów. Motywacją do takich uogólnień jest zazwyczaj potrzeba wykonania
dokładniejszego opisu rozprzestrzeniania epidemii, który wierniej niż schemat
(4.62) oddaje specyfikę choroby. W szczególności liczba grup, na które dzielimy
populację, powinna zależeć od typu infekcji. I tak, na przykład, w modeluSIS
(4.66)
zakłada się istnienie tylko dwóch grup osobników: zdrowych S i chorych I. W
tym modelu osobnicy zainfekowani, powracając do zdrowia ponownie stają się
podatni na ten sam typ patogenu. Uogólnieniem schematu (4.62) jest również
model SIRS, w którym rozważa się wpływ przejściowego okresu uodpornienia
R na dynamikę rozprzestrzeniania się chorób zakaźnych
(4.67)
Ostatnią sekwencję (4.67) wykorzystuje się na przykład do modelowania
wirusów komputerowych. Stan R komputerów w Internecie odpowiada
wtedy komputerom z działającym i mającym aktualne bazy danych
oprogramowaniem antywirusowym. Jeśli jednak administrator komputera nie
zadba na czas o ciągłość licencji oprogramowania, odporna do tej pory
maszyna staje się podatna na ataki wirusów (S) i może zostać zarażona
(I).
W modelu SEIR, sekwencję zmiany stanów (4.62) uzupełnia się natomiast
dodatkowym stanem E (ang. exposed), który reprezentuje osobników w
utajonym stadium choroby
(4.68)
Osobnicy należący do tej grupy, są zainfekowani i mogą zarażać zdrowe
jednostki, często wcale nie będąc świadome tego, że stanowią zagrożenie dla
pozostałych. Z tego typu sytuacją mamy do czynienia w wypadku bardzo
popularnego wirusa wywołującego chorobę zwaną różyczką. Podstawowym
objawem tej choroby jest bladoróżowa wysypka, która po 2 – 3 dniach
znika nie pozostawiając żadnych śladów. Do zarażenia tym wirusem
dochodzi drogą kropelkową. Okres wylęgania wirusa wynosi od 2 do 3
tygodni, przy czym już ok. 7 dni przed wystąpieniem wysypki zaczyna
się okres zaraźliwości. Chory, będąc w utajonej fazie choroby zaczyna
zarażać otoczenie. Okres ten kończy się od 3 do 5 dni po wystąpieniu
wysypki. Choroba, jak to zaznaczono na schemacie (4.68), powoduje trwałą
odporność. Innymi przykładami chorób zakaźnych, do opisu których stosuje
model SEIR, są różnego rodzaju choroby przenoszone drogą płciową, np.
AIDS.
W dalszej części tego podrozdziału zbadamy dynamikę choroby zakaźnej
typu SIS w dwóch różnych społecznościach:
W pierwszej sieć kontaktów interpersonalnych między osobnikami
(węzłami sieci) ma taką samą strukturę, jak klasyczny graf
przypadkowy.
W drugiej węzły reprezentujące osobników badanej populacji tworzą
sieć bezskalową.
Model SIS jest najprostszym modelem rozprzestrzeniania się epidemii, ponieważ stan populacji
w tym modelu jest opisany tylko jedną zmienną I, która reprezentuje liczbę osobników
zainfekowanych14.
Aby zatem opisać dynamikę epidemii w interesujących nas sieciach przypadkowych,
musimy rozwiązać jedno równanie różniczkowe, a nie układ kilku równań.
Pierwowzór takiego równania, tj. równanie (4.64) w układzie równań opisujących
model SIR, omówiliśmy już wcześniej.
Mimo względnej prostoty modelu SIS, korzystając z niego, można
pokazać, w jaki sposób topologia sieci bezskalowej, w przeciwieństwie do
klasycznych topologii sieci regularnych i grafów ER, sprzyja rozprzestrzenianiu
się epidemii. Model SIS jest najprostszy w opisie teoretycznym, ale
jakościowe wnioski płynące z jego analizy są podobne do tych, które
uzyskalibyśmy, analizując pozostałe modele: SIR, SIRS, SEIR i wiele innych.
Model SIS w klasycznych grafach przypadkowych
Rozważmy zatem klasyczny graf
przypadkowy15,
w którym średni stopień losowo wybranego wierzchołka jest równy <k>.
Przyjmijmy też następujące oznaczenia:
I(t) reprezentuje liczbę osobników zainfekowanych (chorych), tj. liczbę
węzłów w stanie I (4.66).
S(t) to liczba osobników podatnych (zdrowych), czyli liczbę węzłów w
stanie S, przy czym
(4.69)
β oznacza prawdopodobieństwo, że w pojedynczym kroku czasowym
(w przedziale czasu dt), zdrowy osobnik zarazi się od chorego
sąsiada16
(rysunek 4.12).
γ to prawdopodobieństwo, że w pojedynczym kroku czasowym chory
osobnik powraca do zdrowia, tj. zmienia stan I → S.
W dalszych obliczeniach będziemy się też często posługiwali parametrem
(4.70)
który nazywiemy tempem rozprzestrzeniania sięepidemii17.
Rys. 4.12:
Sekwencja zmiany stanów dowolnego osobnika (węzła) podczas
rozprzestrzeniania się epidemii typu SIS.
Korzystając z tych oznaczeń, tempo zmiany w
czasie wielkości I(t) można zapisać w postaci równania
różniczkowego18
(4.71)
w którym pierwszy wyraz po prawej stronie reprezentuje średnią liczbę
węzłów, zmieniających podczas pojedynczego kroku czasowego, tj. w
przedziale czasu (t,t + dt), zmieniają swój stan S → I, drugi wyraz zaś
jest średnią liczbą węzłów, które w tym samym czasie doświadczają
przeciwnej zamiany stanów I → S. Postać drugiego wyrazu jest prosta. Jeśli
liczba chorych jest równa I(t), a prawdopodobieństwo wyzdrowienia
wynosi γ, wynika stąd, że średnia liczba ozdrowiałych osobników musi być
równa19γI(t). Podobnie, w pierwszym wyrazie, wyrażenie w okrągłych nawiasach, tj.
<k>I/N, reprezentuje średnią liczbę chorych osobników w najbliższym sąsiedztwie
zdrowego węzła. W nawiasy kwadratowe ujęto zaś prawdopodobieństwo, że
zdrowy węzeł zmieni stan S → I, jeśli w jego otoczeniu jest<k>I/N węzłów
zainfekowanych i wszystkie one, niezależnie od siebie, próbują zarazić zdrowego
sąsiada20.
W końcu, to prawdopodobieństwo, przemnożone przez liczbę zdrowych węzłów
S(t) daje średnią liczbę wierzchołków, które w rozważanym przedziale czasu
zmieniają swój stan z S na I.
Dzieląc obie strony zależności (4.71) przez liczbę wszystkich osobników N
(4.69) otrzymujemy równanie opisujące, w jaki sposób w czasie zmienia się
prawdopodobieństwo i(t) = I(t)/N, że losowo wybrany osobnik tej populacji jest
zainfekowany
(4.72)
gdzie s(t) = 1 − i(t). Korzystając z tego równania, możemy odpowiedzieć na
następujące kluczowe pytania dotyczące rozprzestrzeniania się epidemii. Czy
przy zadanych parametrach β i γ oraz dla znanej początkowej liczby
zainfekowanych osobników i0= i(0) infekcja rozprzestrzeni się i stanie się
powszechna, czy nie? A jeśli się rozprzestrzeni, to jak będzie przebiegał ten
proces w czasie? Czy zacznie zanikać, czy może stanie się chorobą endemiczną?
Okazuje się, że aby odpowiedzieć na większość z postawionych pytań, wcale
nie trzeba rozwiązywać tego równania. Należy jedynie zbadać, w jaki
sposób zachowuje się ono w granicznych przypadkach, dla t = 0 oraz
t →∞.
gdzie i0> 0. Jeśli prawa strona tego równania jest większa od zera,
tj.
(4.74)
oznacza to, że w następnym kroku czasowym prawdopodobieństwo spotkania
zainfekowanych osobników będzie większe niż w chwili początkowej. Dla
zadanych wartości parametrów β i γ, ostatnie stwierdzenie jest prawdziwe
również dla t > 0. Prawdopodobieństwo i(t) będzie się zatem zwiększać w
kolejnych krokach czasowych. Z tego powodu zależność (4.74) można traktować
jak warunek, który muszą spełniać wielkości β,γ,<k>oraz s0, by w rozważanej
populacji, w której sieć kontaktów interpersonalnych między osobnikami
jest równoważna strukturze grafu ER, epidemia mogła się swobodnie
rozprzestrzeniać. Korzystając z definicji tempa epidemii λ (4.70), warunek ten
można zapisać w prostszej do zapamiętania postaci:
(4.75)
Z zależności (4.75) wynika, że jeśli tempo rozprzestrzeniania się patogenu,
wywołującego pewną chorobę zakaźną, jest większe od pewnej progowej
wartości21
(4.77)
wówczas choroba ta ma szansę przybrać w populacji formę epidemii. Wartość
krytyczna tego tempa zależy od gęstości sieci <k>oraz od początkowej liczby
zainfekowanych osobników i0= 1 − s0. Cechą charakterystyczną tego
wyniku, jest to, że istnienie progowej wartości λc> 0, przez zmianę
wartości parametrów β i γ pozwala sterować tempem epidemii. Zwłaszcza
gdy
(4.78)
wspierając różne działania prewencyjne, polegające na przykład na:
zwiększeniu wydatków na służbę zdrowia i ogólnie rozumianą
profilaktykę zdrowotną,
możemy skutecznie obniżyć tempo rozprzestrzeniania się patogenu
(4.79)
i w ten sposób, utrzymując w mocy warunek
(4.80)
zapobiec wybuchowi (lub dalszemu rozprzestrzenianiu się) epidemii.
W końcu, poszukując niezależnych od czasu rozwiązań równania (4.72), tzn.
analizując to równanie w granicy t →∞, otrzymujemy algebraiczne równanie
postaci
(4.81)
gdzie i∞=limt→∞i(t), zaś s∞= 1 − i∞. Zależność ta ma dwa
rozwiązania22
(4.82)
oraz
(4.83)
gdzie λ*c jest krytycznym tempem rozprzestrzeniania się epidemii dla
początkowej liczby zainfekowanych osobników i0≪ 1, tj. dla s0≃ 1. Pierwsze z
tych rozwiązań jest stabilne, gdy epidemia jest w fazie podkrytycznej, tj. dla
λ < λc. Jednak, gdy tempo rozprzestrzeniania się epidemii jest większe od
progowej wartości λc, wówczas epidemia staje się powszechna i badana choroba
nabiera charakteru endemicznego, charakteryzującego się stałą w czasie liczbą
zainfekowanych osobników (4.83).
Rozprzestrzenianie się epidemii w sieciach bezskalowych
Pokażemy na koniec, że w sieciach bezskalowych progowa
wartość tempa rozprzestrzeniania się epidemii λc jest bardzo mała, a w granicy N → 0
jest równa zeru. Oznacza to, że w takich sieciach każda epidemia typu
SIS23,
niezależnie od wartości parametrów β i γ, jak również niezależnie od
początkowej liczby zainfekowanych osobników, będzie się swobodnie
rozprzestrzeniała, w krótkim czasie osiągając stan endemiczny. Chcąc znaleźć
wartość λc w takich sieciach postąpimy w podobny sposób, jak w wypadku
grafów ER, tzn. napiszemy równanie na tempo zmiany liczby osobników
zainfekowanych, a następnie poszukamy stacjonarnych, tzn. niezależnych
od czasu, rozwiązań tego równania i przedyskutujemy stabilność tych
rozwiązań. To pozwoli nam wyznaczyć krytyczne tempo rozprzestrzeniania się
epidemii.
Omawiając proces rozprzestrzeniania się epidemii typu SIS w klasycznych
grafach przypadkowych, posługiwaliśmy się równaniem różniczkowym (4.71), które
opisywało tempo zmiany w czasie liczby zarażonych węzłów. Pisząc to równanie,
milcząco zakładaliśmy, że wszystkie węzły badanego grafu mają taki sam stopień
równy <k>. W sieciach bezskalowych, o potęgowych rozkładach stopni węzłów
P(k) ∝ k−α, w których obok słabo usieciowionych węzłów występują również
wierzchołki mające bardzo dużo krawędzi, takie założenie jest nie do
przyjęcia24.
Z tego powodu omówienie modelu SIS w tych sieciach oprzemy na analizie
równania różniczkowego, opisującego tempo zmiany w czasie liczby zarażonych
węzłów o zadanym stopniu k.
Niech zatem:
Ik(t) reprezentuje liczbę zainfekowanych węzłów o stopniu k,
Sk(t) liczbę podatnych węzłów o tym samym stopniu, przy czym
(4.84)
gdzie P(k) jest rozkładem stopni węzłów badanej sieci, zaś
QI będzie prawdopodobieństwem, że dowolna krawędź sieci prowadzi do chorego
wierzchołka25.
Korzystając z tych oznaczeń, równanie opisujące tempo zmiany w czasie wielkości
Ik(t), można zapisać w postaci
(4.85)
Równanie to jest wierną kopią równania (4.71). Znaczenie kolejnych wyrazów
jego po prawej stronie, jak również znaczenie prawdopodobieństw ujętych w
okrągłe i kwadratowe nawiasy, jest takie samo, jak w grafach ER. Jedyna
różnica polega na tym, że równanie (4.85) opisuje dynamikę zmiany stanów
wierzchołków o zadanym stopniu k, a równanie (4.71) opisuje zachowanie się
węzłów o średnim stopniu, w otoczeniu których znajdują się węzły o takich
samych średnich stopniach.
Dzieląc obie strony tego równania przez liczbę węzłów o zadanym stopniu
Nk (4.84) otrzymujemy opisujące, w jaki sposób w czasie zmienia się
prawdopodobieństwo ik(t) = Ik(t)/Nk, że węzeł, o którym wiemy, że ma k
połączeń do innych wierzchołków, jest zainfekowany
(4.86)
gdzie ik(t) + sk(t) = 1. Następnie, przyrównując prawą stronę tego równania
do zera, otrzymujemy algebraiczne równanie na stacjonarny rozkład
prawdopodobieństwa ik=limt→∞ik(t):
(4.87)
Rozwiązując to równanie otrzymujemy
(4.88)
gdzie parametr λ = β/γ (4.70) nazywamy tempem rozprzestrzeniania się
epidemii.
Przypomnijmy, że w klasycznych grafach przypadkowych równanie (4.81),
będące pierwowzorem równania (4.87), miało dwa rozwiązania. Pierwsze (4.82)
opisywało stan stacjonarny populacji, w której nie doszło do rozprzestrzenienia
się epidemii, ponieważ jej tempo było mniejsze od krytycznego λ < λc. Drugie
rozwiązanie (4.83) opisywało natomiast stan endemiczny choroby, po
rozprzestrzenieniu się epidemii na całą populację, dla λ > λc. Podobna
krytyczność powinna również charakteryzować proces rozprzestrzeniania się
epidemii w sieciach o zadanym rozkładzie stopni wierzchołków P(k), również w
sieciach bezskalowych. Co więcej, krytyczność, o której mowa, powinna być w
jakiś sposób zakodowana w zależności (4.88). Po tym komentarzu, gdy raz
jeszcze przyjrzymy się wyrażeniu (4.88) opisującemu prawdopodobieństwo, że
węzeł o stopniu k jest zainfekowany, zauważymy, że jedynym możliwym źródłem
krytyczności tego wyrażenia jest zachowanie się prawdopodobieństwa
QI. Gdy bowiem QI= 0, również ik= 0. Gdy natomiast QI0, także
ik0.
Przeanalizujmy zatem zachowanie się parametru QI wyrażającego
prawdopodobieństwo, że idąc w dowolnym kierunku losowo wybranej krawędzi
losowo docieramy do chorego wierzchołka. Omawiając
własności modelu konfiguracyjnego, tzn. własności grafów przypadkowych o
zadanym rozkładzie stopni węzłów P(k), często posługiwaliśmy się rozkładem
(4.89)
opisującym prawdopodobieństwo, że przypadkowa krawędź prowadzi do węzła o
stopniu k. Znając ten rozkład, w prosty sposób można wyznaczyć szukany
parametr QI. Aby to zrobić wystarczy zauważyć, że iloczyn Q(k)ik wyraża
prawdopodobieństwo, że losowo wybrana krawędź prowadzi do chorego węzła
mającego k połączeń. Sumując takie iloczyny po wszystkich możliwych
stopniach, otrzymujemy uwikłane równanie na QI
(4.90)
gdzie skorzystaliśmy z wyprowadzonej wcześniej zależności (4.88).
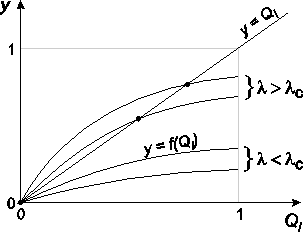
Na rysunku 4.13 pokazano graficzne rozwiązanie tego uwikłanego równania
(4.90). Ponieważ dla QI= 0 wartość funkcji f(QI) jest równa zeru f(0) = 0,
zaś dla QI= 1 oraz λ > 0 jest mniejsza od jedności f(1) < 1, wynika
stąd, że z nachylenia df(QI)/dQI tej funkcji w punkcie QI= 0 można
wnioskować, czy wykres y = f(QI) przecina prostą y = QI tylko raz, dając przy
tym trywialne QI= 0 rozwiązanie równania (4.90), czy może dwa razy:
pierwszy raz dla QI= 0 i drugi raz dla QI0. Pojawienie się tego drugiego
rozwiązania, z którego wynika różne od zera prawdopodobieństwo ik (4.88),
że węzeł o stopniu k jest zainfekowany, świadczy o tym, że epidemia
rozwinęła sie w populacji bez przeszkód, a wywołująca ją choroba stała
się endemiczna. Z tych rozważań wnioskujemy, że warunek opisujący
pojawienie się tego nietrywialnego, tzn. QI0, rozwiązania równania (4.90),
tj.
(4.91)
powinien umożliwić wyznaczenie krytycznej wartości tempa rozprzestrzeniania
się epidemii λc w badanych sieciach.
Rys. 4.13:
Graficzne rozwiązanie równania (4.90
). Oznaczenie umieszczone
na rysunku są zgodne z tymi, których użyto w tekście.
Podstawiając do warunku (4.91) jawną postać funkcji f(QI) (4.90)
otrzymujemy
Z zależności (4.93) wynika, że próg epidemii w badanych sieciach jest
równy
(4.94)
Jeśli bowiem λ > λc (4.93) patogen wywołujący epidemię rozprzestrzenia się w
populacji bez przeszkód prowadząc, w granicy t →∞, do pewnej stałej,
różnej od zera liczby zachorowań (4.88). Gdy natomiast λ < λc epidemia
wygasa.
W sieciach bezskalowych, o potęgowym rozkładzie stopni węzłów
P(k) ~ k−α, gdzie α ∈ (2,3), w których w granicy N →∞ drugi moment
rozkładu P(k) jest nieskończony, próg epidemii jest równy zeru
(4.95)
Oznacza to, że w takich sieciach klasyczne, stosowane dotychczas działania
prewencyjne, mające na celu zmniejszenie tempa rozprzestrzeniania się epidemii,
nie przyniosą pożądanego efektu. W sieciach bezskalowych epidemii nie można
zatrzymać posługując się tradycyjnymi metodami, takimi jak masowe
szczepienia26. To dlatego wirus HIV, rozprzestrzeniający się w bezskalowej sieci
kontaktów seksualnych, jest tak trudny do opanowania. To również
dlatego wirusy komputerowe, których naturalnym środowiskiem jest
Internet, są tak bardzo powszechne. Przedstawiona powyżej,
teoretyczna analiza procesu rozprzestrzeniania się epidemii w sieciach
bezskalowych27
pokazuje, że w walce z wirusami nie mamy prawie żadnych szans na
wygraną.
1Szacuje się, że w tamtych czasach w Europie żyło ok. 85 mln ludzi.
2Pandemią nazywamy epidemię o zasięgu ogólnoświatowym.
3Przykładami takich odzwierzęcych wirusów są m.in. wirus HIV, wirus ptasiej czyświńskiej grypy i w końcu niezwykle groźny wirus SARS, który w ciągu zaledwie jednegomiesiąca, na przełomie marca i kwietnia 2003 roku, zabił przeszło 800 osób z blisko 8 tysięcy, uktórych wykryto objawy zarażenia.
4W 1978 roku państwa zrzeszone w Organizacji Narodów Zjednoczonych (ONZ)podpisały program Zdrowie dla wszystkich 2000, zgodnie z którym postawiono sobieambitny cel całkowitego wyeliminowania gruźlicy do 2000 roku. Oczywiście, nie udałosię zrealizować podstawowych założeń tego projektu. Gruźlica jest nadal chorobąpowszechną. Dzisiaj, patrząc na ten projekt z perspektywy nowych wyników badań nt.rozprzestrzeniania się epidemii w sieciach bezskalowych, wiemy, że nigdy nie miał on szansypowodzenia.
5ang. Acquired Immune Deficiency Syndrome – zespół nabytego niedoboruodporności.
7To jest rozkłady stopni węzłów w sieci kontaktów seksualnych.
8Podobne rezultaty uzyskali szwedzcy badacze, Friderik Liljeros i Christopher Edling zuniwersytetu w Sztokholmie.
9Philip Ball (ur. 1962) – doktor fizyki na Uniwersytecie w Bristolu, absolwent wydziałuchemii na Uniwersytecie w Oksfordzie, autor książek popularnonaukowych, redaktorprestiżowego czasopisma naukowego „Nature”. Jego książka Masa krytyczna została w 2005roku uhonorowana Nagrodą Aventis, przyznawaną przez Towarzystwo Królewskie w Londynienajlepszej książce popularnonaukowej.
10Robak komputerowy jest samoreplikującym się złośliwym oprogramowaniem,podobnym do wirusa komputerowego. Główną różnicą między wirusem a robakiem jest to, żepodczas gdy wirus potrzebuje nosiciela – zwykle jakiegoś pliku wykonywalnego,który modyfikuje, doczepiając do niego swój kod wykonywalny, robak jest pod tymwzględem samodzielny. Rozprzestrzenia się we wszystkich sieciach podłączonych dozarażonego komputera, wykorzystując luki w systemie operacyjnym lub naiwnośćużytkownika.
11O chorobie zakaźnej mówi się, że ma charakter endemiczny, jeśli liczbazachorowań na tę chorobę przez długi czas utrzymuje sie na stałym poziomie.
12Tak naprawdę, wyeliminowanie części wirusów zawdzięczamy jedynie skończonymrozmiarom sieci komputerowej i nieustannej aktualizacji sprzętu i oprogramowaniakomputerowego, powodującego, że część wirusów się po prostu starzeje i umiera „śmierciąnaturalną”.
13W międzyczasie Martinus W. Beijerinck (1851–1931), holenderski botanik imikrobiolog, odkrył wirusy.
14Zakładając stały rozmiar badanego układu N, liczba osobników podatnych jest równaS = N − I.
15Model SIS w klasycznych grafach przypadkowych jest całkowicie równoważnymodelowi SIS w tzw. dokładnie wymieszanych populacjach, w których każdy osobnik typu S(lub I) ma jednakowe prawdopodobieństwo spotkania osobnika typu I (odpowiednio S).
17W części prac poświęconych modelowaniu epidemii zamiast parametru λ możnaspotkać parametr ρ = λ−1, który nosi nazwę względnego współczynnika zdrowienia. Naszymzdaniem, ten pierwszy parametr jest sensowniejszy, szczególnie w odniesieniu do siecibezskalowych.
18Równanie (4.71) ma postać równania kinetycznego.
19Tak naprawdę ta średnia jest wartością oczekiwaną rozkładu dwumianowego, w którym liczba prób jest równa I(t), a prawdopodobieństwo pojedynczego sukcesuwynosi γ.
20Prawdopodobieństwo to jest równe prawdopodobieństwu, że przynajmniej jednemuwęzłowi uda się tego dokonać w przedziale czasu dt, tj. 1 − (1 − β)I1≃ βI1, gdzieI1= <k>/N jest średnią liczbą zainfekowanych osobników w otoczeniu zdrowegowęzła.
21W przypadku, gdy liczba chorych osobników jest dużo mniejsza od rozmiaru całejpopulacji, tj. s0≃ 1, wtedy krytyczne tempo rozprzestrzeniania się epidemii (4.77) zależyjedynie od struktury sieci.
22Z punktu widzenia fizyki statystycznej, rozprzestrzenianie się choroby zakaźnej w siecio zadanej strukturze jest procesem nierównowagowym. Wartość progowa temparozprzestrzeniania się epidemii λcokreśla punkt krytyczny nierównowagowej przemiany fazowej.
23Dotyczy to również innych znanych modeli rozprzestrzeniania się epidemii: SIR,SEIR, SIRS itd.
24Pojęcie bezskalowości zostało dokładnie omówione na wcześniejszym wykładzie .
25W grafach ER to prawdopodobieństwo wynosiło QI= I(t)∕N.
26Na konferencji NetSCI’08 (Norwich, Wielka Brytania, czerwiec 2008), podczas którejobchodzono dziesięciolecie nauki o sieciach złożonych, słynny epidemiolog, prezydentprestiżowego Królewskiego Towarzystwa Naukowego w Londynie (Royal Society of London)Robert May (Baron May of Oxford), (ur. 1936), uznał ten wynik za jedno z najważniejszychosiągnięć tej nowej, interdyscyplinarnej dziedziny.
27Do tej klasy sieci należy większość sieci rzeczywistych.
 Wielkie epidemie, takie jak epidemia dżumy, zwanej potocznie czarną śmiercią,
która spustoszyła czternastowieczną Europę, zabijając trzecią część jej
mieszkańców1 ,
lub pandemia2
grypy hiszpanki, na którą w czasie pierwszej wojny światowej zmarło
przeszło 100 mln ludzi na całym świecie, zdarzały się dosyć często
w historii naszej cywilizacj. Sukcesy medycyny sprawiły
jednak, że dzisiaj z dystansem traktujemy prasowe doniesienia na temat
nowych szczepów grypy czy też nieznanych dotychczas odzwierzęcych
wirusów3 .
Wierzymy, że współczesna, stojąca na wysokim poziomie służba zdrowia nas
ochroni, a odpowiednie środki finansowe, masowe szczepienia, w wyjątkowych
przypadkach zaś po prostu odosobnienie i kontrola chorych osobników rozwiąże
resztę problemów. W tym podrozdziale pokażemy, że taki optymizm jest
bezpodstawny. Prawda jest taka, że mamy się czego obawiać. Bezskalowa
struktura sieci społecznych sprzyja bowiem rozprzestrzenianiu się wirusów. Z
tego właśnie powodu w walce z różnymi chorobami zakaźnymi niemal zupełnie
nie mamy szans na wygraną. To dlatego choroby takie jak różyczka, grypa,
gruźlica4 ,
a nawet AIDS są ciągle, mimo zakrojonej na szeroką skalę profilaktyki
zdrowotnej, tak bardzo powszechne.
Wielkie epidemie, takie jak epidemia dżumy, zwanej potocznie czarną śmiercią,
która spustoszyła czternastowieczną Europę, zabijając trzecią część jej
mieszkańców1 ,
lub pandemia2
grypy hiszpanki, na którą w czasie pierwszej wojny światowej zmarło
przeszło 100 mln ludzi na całym świecie, zdarzały się dosyć często
w historii naszej cywilizacj. Sukcesy medycyny sprawiły
jednak, że dzisiaj z dystansem traktujemy prasowe doniesienia na temat
nowych szczepów grypy czy też nieznanych dotychczas odzwierzęcych
wirusów3 .
Wierzymy, że współczesna, stojąca na wysokim poziomie służba zdrowia nas
ochroni, a odpowiednie środki finansowe, masowe szczepienia, w wyjątkowych
przypadkach zaś po prostu odosobnienie i kontrola chorych osobników rozwiąże
resztę problemów. W tym podrozdziale pokażemy, że taki optymizm jest
bezpodstawny. Prawda jest taka, że mamy się czego obawiać. Bezskalowa
struktura sieci społecznych sprzyja bowiem rozprzestrzenianiu się wirusów. Z
tego właśnie powodu w walce z różnymi chorobami zakaźnymi niemal zupełnie
nie mamy szans na wygraną. To dlatego choroby takie jak różyczka, grypa,
gruźlica4 ,
a nawet AIDS są ciągle, mimo zakrojonej na szeroką skalę profilaktyki
zdrowotnej, tak bardzo powszechne. Kim był Pacjent Zero? Nazywał się Gaetan Dugas (1953–1984) i pracował
jako steward w kanadyjskich liniach lotniczych. Był gejem, który wykazywał
niezwykłą aktywność seksualną. Z jego późniejszych wypowiedzi wynikało, że
miewał średnio
Kim był Pacjent Zero? Nazywał się Gaetan Dugas (1953–1984) i pracował
jako steward w kanadyjskich liniach lotniczych. Był gejem, który wykazywał
niezwykłą aktywność seksualną. Z jego późniejszych wypowiedzi wynikało, że
miewał średnio 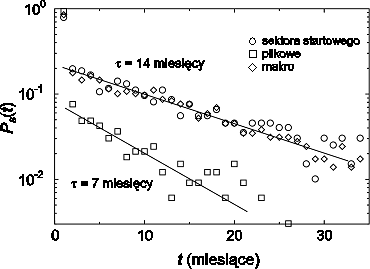
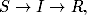
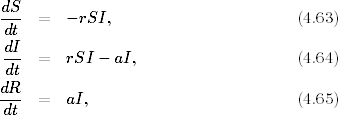
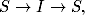
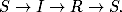
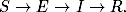
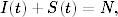
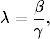
![[ ( )]
dI(t) I(t)
dt = β 〈k〉 N S(t)− γI(t),](rys/rys4_74x.png)
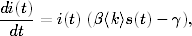
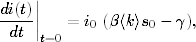
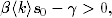
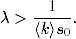
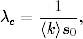
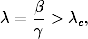
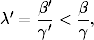
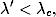
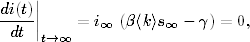
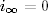
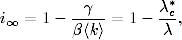
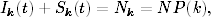
![dIk(t)= [β(kQI )]Sk(t)− γIk(t).
dt](rys/rys4_88x.png)
![dik(t)-
dt = [β(kQI )]sk(t)− γik(t),](rys/rys4_89x.png)