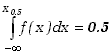|
|
Jeśli wynik powtarzanego w tych samych warunkach pomiaru przyjmuje różne
wartości, to mówimy, że obarczony jest niepewnościami przypadkowymi i
traktujemy go jako zdarzenie losowe. Zdarzeniu losowemu przypisujemy określoną
wartość tzw. zmiennej losowej. W zależności od tego, jakie wartości
może przyjmować dana zmienna losowa, mówimy o zmiennych losowych typu ciągłego
lub typu dyskretnego (skokowego). Uwaga techniczna - zmienne losowe
oznaczać będziemy symbolami prostymi
![]() itd.
itd.
Dla opisu własności zmiennych losowych warto mieć na uwadze, że prawdopodobieństwo zdarzenia losowego A możemy określić poprzez stosunek
|
|
(2.1.1) |
gdzie przy N wykonanych doświadczeniach wystąpiło n razy zdarzenie A. Definicja ta jest łatwa do zrozumienia na przykładzie rzutów kostką do gry gdzie dla idealnej kostki prawdopodobieństwo wyrzucenia danej liczby całkowitej z przedziału od 1 do 6 wynosi 1/6, prawdopodobieństwo wyrzucenia liczby parzystej wynosi 1/3 itd. Ta liczby, które możemy uzyskać w rzutach kostką do gry, to właśnie przykłady liczb losowych typu dyskretnego.
Jakie wartości wyników pomiarów (zmiennych losowych) są bardziej, a jakie
mniej prawdopodobne? O tym mówi kształt rozkładu zmiennych losowych. Dla
opisu rozkładu zmiennych losowych wprowadza się pojęcie tzw.
dystrybuanty F(x) zmiennej losowej
![]() Wielkość ta określona jest jako prawdopodobieństwo takiego zdarzenia, w którym
wartość zmiennej losowej
Wielkość ta określona jest jako prawdopodobieństwo takiego zdarzenia, w którym
wartość zmiennej losowej
![]() jest mniejsza od danej liczby x.
jest mniejsza od danej liczby x.
|
|
(2.1.2) |
Zauważmy, że kiedy wartość liczby x zmierza do nieskończoności, to wartość dystrybuanty określa prawdopodobieństwo zdarzenia pewnego tj. zmierza do jedynki, kiedy zaś wartość liczby x zmierza do minus nieskończoności, to wartość dystrybuanty zmierza do zera:
|
|
(2.1.3) |
Jeśli dystrybuanta jest funkcją ciągłą to wówczas funkcja określona jako
|
|
(2.1.4) |
zwana jest funkcją gęstości prawdopodobieństwa lub krótko, gęstością
prawdopodobieństwa zmiennej losowej
![]() .
Zgodnie z tą definicją, gęstość prawdopodobieństwa zmiennej losowej
.
Zgodnie z tą definicją, gęstość prawdopodobieństwa zmiennej losowej
![]() określa
prawdopodobieństwo zajścia zdarzenia w którym
określa
prawdopodobieństwo zajścia zdarzenia w którym
![]() ,
zaś prawdopodobieństwo tego, że zmienna losowa przyjmie wartość z przedziału
pomiędzy a i b określone jest wyrażeniem
,
zaś prawdopodobieństwo tego, że zmienna losowa przyjmie wartość z przedziału
pomiędzy a i b określone jest wyrażeniem
|
|
(2.1.5) |
Wynika z tego również, że spełniony jest tzw. warunek normalizacyjny
|
|
(2.1.6) |
Ważną wielkością charakteryzującą rozkłady zmiennych losowych jest wartość przeciętna zwana też wartością oczekiwaną. Wartość ta dla zmiennych losowych dyskretnych określona jest jako suma (po wszystkich możliwych wartościach zmiennej losowej) iloczynów wartości zmiennej losowej i odpowiadającego tej wartości prawdopodobieństwa.
|
|
(2.1.7) |
Dla zmiennych losowych ciągłych wartość oczekiwana określona jest poprzez funkcje gęstości prawdopodobieństwa
|
|
(2.1.8) |
Czasami interesuje nas rozkład nie samej zmiennej losowej, ale wielkości
![]() będącej funkcją zmiennej losowej
będącej funkcją zmiennej losowej
![]() .
Funkcja taka jest również zmienną losową dla której możemy określić dystrybuantę
i gęstość prawdopodobieństwa. Wartość oczekiwana dla funkcji zmiennej
losowej dyskretnej określa wzór
.
Funkcja taka jest również zmienną losową dla której możemy określić dystrybuantę
i gęstość prawdopodobieństwa. Wartość oczekiwana dla funkcji zmiennej
losowej dyskretnej określa wzór
|
|
(2.1.9) |
zaś dla zmiennej losowej o rozkładzie ciągłym mamy
|
|
(2.1.10) |
Wielkie znaczenie ma funkcja postaci
|
|
(2.1.11) |
Wartość oczekiwaną dla tak zdefiniowanej funkcji nazywa się momentem rzędu l względem wartości c
|
|
(2.1.12) |
Kiedy za c przyjmiemy wartość oczekiwaną, wówczas tak określony moment nazywamy momentem centralnym
|
|
(2.1.13) |
Zauważmy, że możemy łatwo zapisać dwa pierwsze momenty centralne; rzędu zerowego i rzędu pierwszego
|
|
(2.1.14) |
Moment centralny rzędu drugiego,
|
|
(2.1.15) |
zwany jest wariancją i odgrywa fundamentalną rolę w analizie niepewności pomiarowych. Kiedy wyniki pomiarów traktujemy jako wartości zmiennej losowej, to zgodnie z definicją, moment ten jest wartością przeciętną kwadratu różnic pomiędzy wynikami poszczególnych pomiarów a wartością oczekiwaną (która odpowiada wartości rzeczywistej) mierzonego obiektu. Zgodnie z definicją (2.1.10) moment ten określony jest wzorem
|
|
(2.1.16) |
Dodatnio określony pierwiastek z wariancji nosi nazwę odchylenia standardowego
|
|
(2.1.17) |
i jest podstawową wielkością charakteryzującą rozrzut wyników pomiarów wokół wartości przeciętnej (rzeczywistej).
Trzeci moment ![]() jest miarą asymetrii rozkładu i nazywany bywa współczynnikiem skośności
(skośnością) rozkładu. Częściej stosowany jest bezwymiarowy parametr
zwany współczynnikiem asymetrii zdefiniowany jako
jest miarą asymetrii rozkładu i nazywany bywa współczynnikiem skośności
(skośnością) rozkładu. Częściej stosowany jest bezwymiarowy parametr
zwany współczynnikiem asymetrii zdefiniowany jako
|
|
(2.1.18) |
Dla rozkładów symetrycznych parametr ten równy jest zeru.
Rozpatrzmy najprostszy rozkład zmiennej losowej tzw. rozkład równomierny (jednostajny). W rozkładzie tym gęstość prawdopodobieństwa zachowuje wartość stałą w zadanym przedziale tj:
|
|
(2.1.19) |
Zapiszmy warunek normalizacyjny określony wzorem (2.1.6)
|
|
(2.1.20) |
Wynika z tego, że gęstość prawdopodobieństwa w przedziale od a do b wynosi
|
|
(2.1.21) |
Znając gęstość prawdopodobieństwa możemy wyznaczyć dystrybuantę wykorzystując wzór (2.1.4)
|
|
(2.1.22) |
Wartość oczekiwaną obliczamy zgodnie ze wzorem (2.1.8)
|
|
(2.1.23) |
W ten sam sposób, posługując się wzorem (2.1.16), otrzymujemy wzór na wariancję w rozkładzie równomiernym
|
|
(2.1.24) |
Rozkład równomierny jest nie tylko dobrym przykładem dla ilustracji podstawowych wielkości charakteryzujących rozkłady zmiennych losowych i ich parametry. Stanowi też podstawę generacji Monte-Carlo różnorodnych rozkładów statystycznych. Przykładowe rozkłady generowane są z użyciem programu EXCEL
W niektorych praktycznych zastosowaniach wygodnie jest zdefiniować funkcję postaci
|
|
(2.1.25) |
Wartość oczekiwana dla tak zdefiniowanej funkcji równa jest zeru, bowiem
|
|
(2.1.26) |
Wariancja równa jest jedności
|
|
(2.1.27) |
Tak zdefiniowaną zmienną losową nazywamy zmienną znormalizowaną. Zmienne tago typu dla wielu rozkładów są podawane w postaci tablic. Znając wartości funkcji dla rozkładu znormalizowanego mozna łatwo otrzymać wartości dla rozkładu o danej wartości oczekiwanej i wariancji posługujac się zależnością (2.1.25).
Użyteczne bywa niekiedy zdefiniowanie tzw. wartości modalnej,![]() ,
dla której
,
dla której
|
|
(2.1.28) |
i która dla rozkładów mających określoną pierwszą i drugą pochodną, może być wyznaczona z warunków
|
|
(2.1.29) |
Kiedy rozkład gęstości prawdopodobieństwa posiada jedno maksimum, nazywamy go jednomodalnym, kiedy posiada ich więcej, mamy do czynienia z rozkładem wielomodalnym.
Wartość zmiennej losowej, dla której dystrybuanta równa jest 1/2 , tj dzielącej rozkład prawdopodobieństwa na dwie części o równym prawdopodobieństwie, oznaczana x0.5, zwana jest medianą. Mamy zatem
|
|
(2.1.30) |
Dla zmiennych losowych o rozkładzie ciągłym możemy napisać
|
|
(2.1.31) |
Podobnie możemy zdefiniować wielkości dzielące rozkład prawdopodobieństwa na więcej częsci. Na przykład wielkości x0.25 oraz x0.75 dla których mamy
|
|
(2.1.32) |
nazywamy odpowiednio dolnym i górnym kwartylem. Ogólnie, wielkości tego typu nazywamy kwantylami.
Nietrudno zauważyć, że dla jednomodalnych i ciągłych rozkładów symetrycznych, wartość przeciętna, modalna oraz mediana pokrywają się. Nie zachodzi to jednak dla rozkładów asymetrycznych.
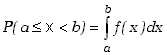
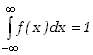
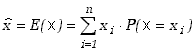
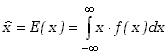
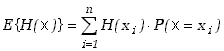
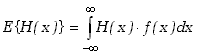
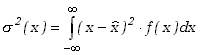
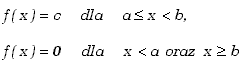 .
.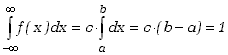
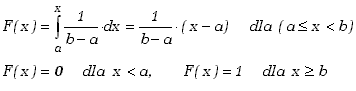
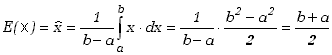
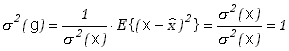 .
.