From Łukasz Graczykowski
(Difference between revisions)
|
|
| Line 2: |
Line 2: |
| | == Zadanie == | | == Zadanie == |
| | | | |
| - | Część pierwsza: liniowy kongruentny generator liczb losowych | + | ''Część pierwsza'': '''liniowy kongruentny generator liczb losowych''' |
| | | | |
| | Należy napisać generator liczb pseudolosowych oraz zapisać wygenerowane liczby do pliku. | | Należy napisać generator liczb pseudolosowych oraz zapisać wygenerowane liczby do pliku. |
| Line 26: |
Line 26: |
| | * m=32363 i a=157. | | * m=32363 i a=157. |
| | | | |
| - | | + | ''Część druga'': '''test widmowy''' |
| - | Część druga: test widmowy | + | |
| | | | |
| | Należy przeprowadzić test widmowy aby przetestować jakość generatora. By to zrobić należy narysować na płaszczyźnie punkty o współrzędnych <code>(x[n], x[n+1])</code>. Uzyskany obraz utworzy wzór przypominający widmo generatora - stąd nazwa testu. | | Należy przeprowadzić test widmowy aby przetestować jakość generatora. By to zrobić należy narysować na płaszczyźnie punkty o współrzędnych <code>(x[n], x[n+1])</code>. Uzyskany obraz utworzy wzór przypominający widmo generatora - stąd nazwa testu. |
| Line 38: |
Line 37: |
| | | | |
| | | | |
| - | Część trzecia: Generacja liczb losowych oparta na transformacji rozkładu jednorodnego | + | ''Część trzecia'': '''Generacja liczb losowych oparta na transformacji rozkładu jednorodnego''' |
| | | | |
| | Dowolna funkcja zmiennej losowej jest zmienną losową. Powstaje więc pytanie jaka jest gęstość zmiennej losowej Y jeżeli znana jest gęstość <code>f(x)</code>. Zakładamy że prawdopodobieństwo <code>g(y)dy</code> jest równe <code>f(x)dx</code> gdzie <code>dx</code> odpowiada wartością <code>dy</code>. Warunek jest spełniony dla odpowiednio małych <code>dx</code>. Wynika stąd, że: | | Dowolna funkcja zmiennej losowej jest zmienną losową. Powstaje więc pytanie jaka jest gęstość zmiennej losowej Y jeżeli znana jest gęstość <code>f(x)</code>. Zakładamy że prawdopodobieństwo <code>g(y)dy</code> jest równe <code>f(x)dx</code> gdzie <code>dx</code> odpowiada wartością <code>dy</code>. Warunek jest spełniony dla odpowiednio małych <code>dx</code>. Wynika stąd, że: |
Revision as of 07:49, 26 March 2012
Zadanie
Część pierwsza: liniowy kongruentny generator liczb losowych
Należy napisać generator liczb pseudolosowych oraz zapisać wygenerowane liczby do pliku.
Stworzony generator powinien opierać się na wzorze:
x[j+1] = ( a*x[j] + c ) mod m.
Generator taki nazywamy generatorem LCG - czyli generatorem liniowym kongruentnym. Zadanie pewnej wartości poczatkowej x[0] definiuje nam zatem cały ciąg. Ponadto jest to ciąg okresowy. Okres zależy od doboru parametrów i przy spelnieniu kilku warunków osiąga maksymalnie wartość m. Warunki te to:
- c i m nie maja wspolnych dzielników
- b = a-1 jest wielokrotnoscia kazdej liczby pierwszej p, ktora jest dzielnikiem liczby m
- b jest wielokrotnością 4 jesli m tez jest wielokrotnością 4.
Dla uproszczenia należy przyjąć c = 0, otrzymując w ten sposób multiplikatywny liniowy generator kongruentny (MLCG).
- Wartości a oraz m powinny być łatwe do modyfikacji w programie.
Efektem działania makra powinien być plik nazwa.dat zawierający ciąg wygenerowanych liczb dla zadanych parametrów. Makro należy uruchomić trzy razy, otrzymując trzy pliki: losowe1.dat, losowe2.dat, losowe3.dat, dla parametrów odpowiednio:
- m=7 i a=3,
- m=97 i a=23,
- m=32363 i a=157.
Część druga: test widmowy
Należy przeprowadzić test widmowy aby przetestować jakość generatora. By to zrobić należy narysować na płaszczyźnie punkty o współrzędnych (x[n], x[n+1]). Uzyskany obraz utworzy wzór przypominający widmo generatora - stąd nazwa testu.
Jeśli punkty będą rozłożone równomiernie generator można uznać za dobry. Jeśli zdecydowanie widać pewną okresowość - punkty powtarzają się wielokrotnie - generator nie działa poprawnie. Oczywiście na rozłożenie punktów wpływa jedynie dobór parametrów a i m.
- Do tworzenia wykresów widma poleca się użycie obiektów TH2D.
Wynikiem działania programu powinny być trzy wykresy widma uzyskane na podstawie uprzednio zapisanych plików losowe1.dat, losowe2.dat, losowe3.dat.
Część trzecia: Generacja liczb losowych oparta na transformacji rozkładu jednorodnego
Dowolna funkcja zmiennej losowej jest zmienną losową. Powstaje więc pytanie jaka jest gęstość zmiennej losowej Y jeżeli znana jest gęstość f(x). Zakładamy że prawdopodobieństwo g(y)dy jest równe f(x)dx gdzie dx odpowiada wartością dy. Warunek jest spełniony dla odpowiednio małych dx. Wynika stąd, że:
g(y) = dy/dx f(x)
Teraz jeżeli założymy, że gęstość prawdopodobieństwa f(x) = 1 dla 0<=x<=1 i f(x) = 0 dla x<= 0 i x>1 to powyższe równanie możemy zapisać w postaci:
g(y)dy = dx = dG(y),
gdzie G(y) jest dystrybuantą zmiennej losowej Y. Co po całkowaniu daje nam
x = G(y) => y = G-1(x).
Jeśli zmienna losowa X ma rozkład jednostajny na odcinku pomiędzy 0 i 1 oraz jeśli znana jest funkcja odwrotna G^-1(x) to funkcja g(y) opisuje gęstość prawdopodobieństwa rozkładu zmiennej losowej Y.
Używając tej metody należy wygenerować 10000 liczb z rozkładu:
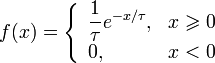
Dla tau = 2:
- Należy wygenerować 10000 liczb z rozkładu 0 do 1 używając generatora z części pierwszej.
- Analitycznie (na kartce) policzyć dystrybuantę tego rozkładu, a następnie funkcję odwrotną.
- Wygenerować rozkład f(x) - wrzucając wygenerowane wartości do histogramu - korzystając z:
- Liczb wygenerowanych z pliku.
- Standardowego generatora ROOT'a gRandom->Rndm(1).
- Narysować na jednym wykresie histogram (odpowiednio unormowany) oraz teoretyczną funkcję f(x) (obiekt TF1).
