Statystyczna Eksploracja Danych
LABORATORIUM 3
MACIERZ POMYŁEK
Na dzisiejszych zajęciach zajmiemy się przede wszystkim metodami oceny jakości klasyfikatorów. Zgodnie z Wykładem 3 podstawowym obiektem, który ułatwi nam pracę jest macierz pomyłek, oznaczana na potrzeby tych ćwiczeń jako \(\mathbf{CM}\). Poszczególne pola tej macierzy
są określane jako TRUE NEGATIVE (dane: negatywne, predykcja: negatywna), FALSE POSITIVE (dane: negatywne, predykcja: pozytywna), FALSE NEGATIVE (dane: pozytywne, predyckja: pozytywna) oraz TRUE POSITIVE (dane: pozytywne, predykcja: pozytywna). Sumowanie rzędów \(\mathbf{CM}\) daje informacje o oryginalnych klasach, sumowanie kolumn - o przewidywanych. Wygodnym wskaźnikiem jakości klasyfikatora jest jego dokładność (ACCURACY) zdefiniowana jako
innymi są FALSE POSITIVE RATE (FPR, 1 - specificity) oraz TRUE POSITIVE RATE (TPR, sensitivity)
Dla ustalenia uwagi znów zaczynamy od nieśmiertelnego rozkładu Gaussa w 2D. Tym razem zdefiniujemy funkcję draw.data.gauss(), którą będziemy wykorzystwać do losowania obserwacji z tego rozkładu (dodatkowo od razu ładujemy potrzebne biblioteki)
Następnie losujemy obserwacje z rozkładów o zadanych parametrach (liczności \(n_1\), \(n_2\), wektory średnich \(\mathbf{m}_1\) i \(\mathbf{m}_2\) oraz macierze kowariancji \(\mathbf{S}_1\) i \(\mathbf{S}_2\)) i na takich danych, uważanych od tej chwili za PU (próba ucząca) budujemy klasyfikatory: LDA, QDA, a także naiwnego Bayesa
Teraz skonstruujemy funkcję CM.large(), której celem będzie wyznaczenie macierzy pomyłek, a następnie obliczenie istotnych, wyżej wymienionych cech, tzn. dokładności, TN, TP, FPR, TPR. Kolejnym krokiem będzie, znane już z poprzednich zajęć, dokonanie klasyfikacji za pomocą metody powtórnego podstawienia. Dodatkowo efekty działania funkcji CM.large() dla różnych klasyfikatorów umieścimy w jendej ramce danych tak, aby łatwo można było je porównać.
otrzymując np. taki efekt
ACC TP TN TPR.2 FPR.1
LDA 0.8643 52 69 0.8667 0.1375
QDA 0.8714 50 72 0.8333 0.1000
NB 0.8643 52 69 0.8667 0.1375
Powyższa tabela sugeruje, że wszystkie 3 testowane klasyfikatory miały podobne statystyki i ciężko mówić tu o jakimś "zwycięzcy". Trzeba zwrócić tu uwagę na fakt, że dokonywaliśmy powtórnego podstawienia, a więc otrzymane przez nas wartości można traktować jako dość "optymistyczne", gdyż klasyfikatory przewidywały przynależność do klas tych samych obserwacji, za pomocą których były trenowane. Należałoby więc powtórzyć te procedury dla zestawu innych danych (PW - próby walidacyjnej), co realizuje poniższy kod
z następującym rezultatem
ACC TP TN TPR.2 FPR.1
LDA 0.8167 23 26 0.7667 0.1333
QDA 0.8667 25 27 0.8333 0.1000
NB 0.8667 25 27 0.8333 0.1000
Jak widać, dla LDA w tym konkretnym przypadku jest kilkuprocentowy spadek, natomiast dla innych klasyfikatorów różnica jest minimalna.
KRZYWA ROC
Powyższe wartości (ACC, FPR, TPR) są punktowe, tzn. zakładają ustalony próg prawdopodobieństwa a posteriori, powodujący, że dana obserwacja zostaje przypisana do konkretnej klasy (dokładniej: próg równy 1/2). Czasem jednak istotne pytaniem staje się: jaki jest profil danego klasyfikatora, tzn. jak się zachowuje przy założeniu nierównego traktowania przynależności do klas. Taki profil często przedstawiany jest w postaci krzywej ROC (receiver-operating curve), gdzie na osi X zostają odłożone wartości FPR, natomiast na osi Y - TPR dla różnych poziomów odcięcia, czyli progów prawdopodobieństw a posteriori np. \(p(2|\mathbf{x})\).
W celu otrzymania krzywej ROC musimy nieco zmodyfikować funkcję odpowiedzialną za wyznaczanie wartości FPR i TPR
Tworzymy też funkcję get.roc.values(), która realizuje następujące cele: pobiera wartości prawdopodobienstw a posteriori dla danej klasy, sortuje je i dla każdego z nich wywołuje funkcję CM.values(). W ten sposób do powyższej funkcji przekazywany jest wartość prawdopodobieństwa, która ma być traktowana jako próg \(\tau\)- obserwacje z \(p(2|\mathbf{x})\) wyższą niż \(\tau\) są klasyfikowane jako pochodzące z klasy "2".
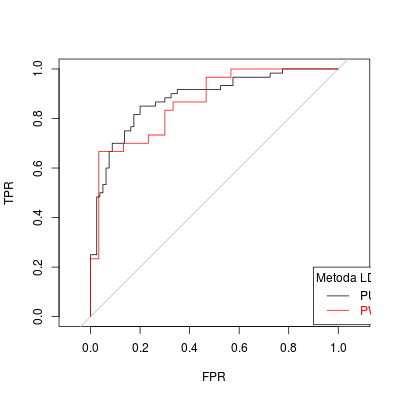
Możemy w końcu uruchomic liczenie ROC dla dówch przypadków LDA: PU oraz PW i porównać efekty na jedynm rysunku.
Rysunek 3.1
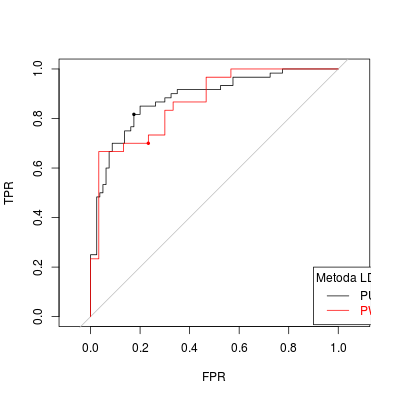
Oczywiście, możemy również odłożyć na krzywej ROC punkty, które odpowiadają konkretnym wartościom (np. tym, związanym z konkretnymi klasyfikatorami).
Rysunek 3.2
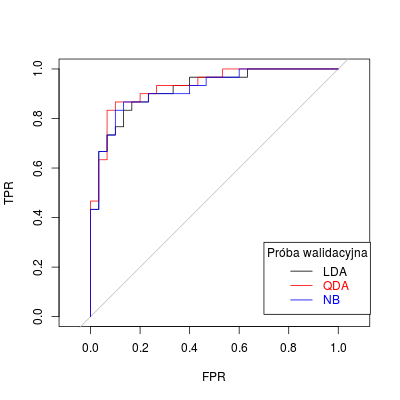
Wreszcie, a może przede wszystkim, krzywa ROC służy do porównywania różnych klasyfikatorów.
Rysunek 3.3
KROSWALIDACJA
W przypadku braku możliwości skorzystania z próby walidacyjnej (tzn. braku możliwości wydzielenia części danych) korzysta się z metody kroswalidacji (walidacji krzyżowej). W tym celu dzieli się dane na kilka (np. 5 lub 10) części, trenuje się klasyfikator na próbie powstałej przez usunięcie jednej części a testuje się na tej usuniętej. Procedurę powtarza się dla każdej częsci, zliczając pomyłki, a następnie sumując i dzieląc przez liczbę elementów, w ten sposób otrzymując oszacowanie błędu klasyfikatora.
Do wykonania kroswalidacji wykorzystamy następujące dwie funkcje
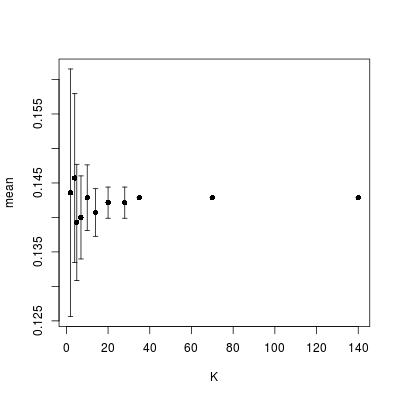
Aby przetestować działanie kroswalidacji na naszych danych, dokonamy jej 10-krotnie i dla każdego dzielnika (tzn. liczby, która dzieli oryginalne dane na całkowitą liczbę pseudoprób). Wyznaczymy wartości średne i odchylenia i korzystając z funkcji errorbar() z pakietu Hmisc (do instalacji), przekonamy się, jak różnią się wyniki
Rysunek 3.4