Statystyczna Eksploracja Danych
LABORATORIUM 10
ANALIZA SKŁADOWYCH GŁOWNYCH
Jednym z zadań eksploracji danych jest redukcja wymiaru, czyli określenie, które ze składowych wektora obserwacji są nieistotne lub też jakie inne kombinacje składowych mogą się okazać przydatne do dalszej analizy. Standardową metodą redukcji wymiaru jest analiza składowych głównych (PCA - principal component analysis). Polega ona na znalezieniu nowego kierunku, który maksymalizuje wariancję zrzutowanych na niego obserwacji. Następnie szukamy kolejnego kierunku, również o jak największej wariancji, tyle, że ortogonalnego do poprzedniego etc. Okazuje się, że takie cechy odpowiadają wektorom własnym związanym z kolejnymi wartościami własnymi (począwszy od największej).
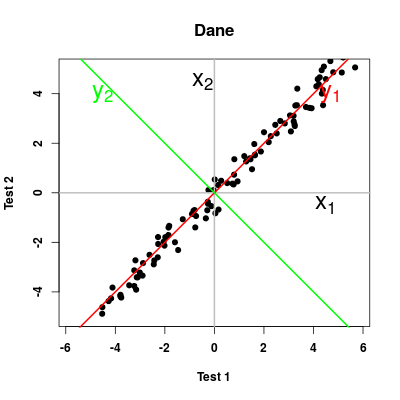
Zaczynamy od przykładu ilustrującego podstawowe cechy PCA dla sztucznie wykreowanych danych postaci \(y + \eta = x + \zeta\), gdzie \(\eta\) i \(\zeta\) są szumem z rozkładu jednorodnego.
Rysunek 10.1
Otrzymalismy spodziewany wykres, gdzie zależność \(y=x\) jest lekko zaburzona ale dalej bardzo wyraźna. Nie uciekając się do generycznej funkji realizującej PCA, sami możemy policzyć skłądowe główne poprzez wyznaczenie wektorów i wartości własnych macierzy kowariancji \(\mathbf{S}\) lub macierzy korelacji \(\mathbf{Sc}\)
$values
[1] 17.36473319 0.06932368
$vectors
[,1] [,2]
[1,] 0.6961527 -0.7178938
[2,] 0.7178938 0.6961527
print(eSc)
$values
[1] 1.992039893 0.007960107
$vectors
[,1] [,2]
[1,] 0.7071068 -0.7071068
[2,] 0.7071068 0.7071068
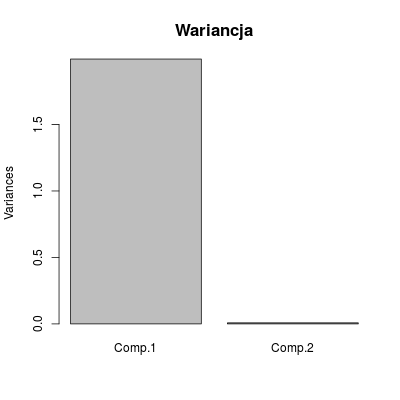
Teraz wykorzystamy już funkcję princomp() do wykonania PCA. Szczególnie istotne będą jej pola $sdev oraz $loadings - pierwsze pokazuje wartości odchylenia stadardowego związane z poszczególnymi składowymi, a drugie wektory ładunkow PCA. Przeciązona funkcja plot() ilustruje wartości odchylenia
Comp.1 Comp.2
1.992039893 0.007960107
Rysunek 10.2
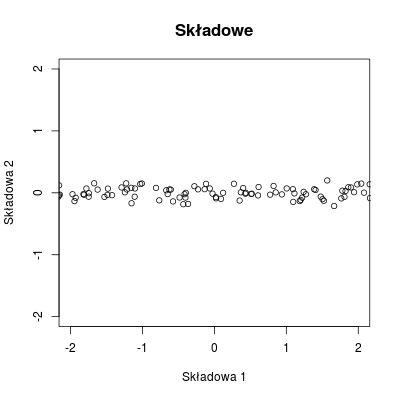
natomiast wykres punktów w nowych współrzędnych dobrze ilustruje faktyczną jednowymiarowość problemu.
Rysunek 10.3
NIELINIOWA ANALIZA SKŁADOWYCH GŁOWNYCH
W wielu przypadkach zwykła analiza składowych głównych nie daje pożądanego rezultatu.
Rysunek 10.4
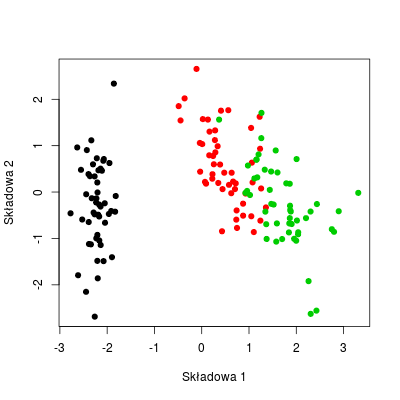
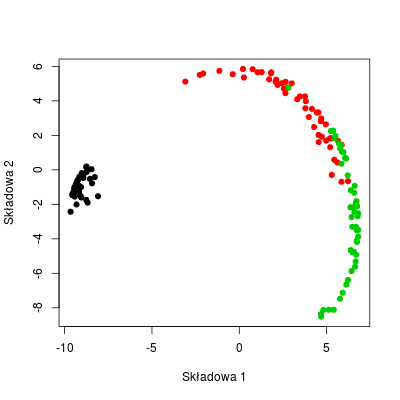
Można wtedy skorzystać z nieliniowej wersji PCA, tj. PCA "wyposażonego" w jądro (kernel) o opowiedniej postaci. Taką opcje oferuje funkcja kpca() z biblioteki kernlab
Rysunek 10.5
SKALOWANIE WIELOWYMIAROWE
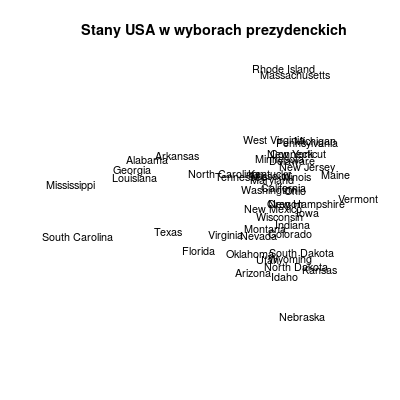
Bardzo ciekawą i prostą w wizualizacji metodą jest skalowanie wielowymiarowe (ang. multidimensional scaling - MDS). W ogólnym ujęciu, za pomocą tego podejścia (funkcja cmdscale())możliwe jest przedstawienie odległości pomiędzy poszczególnymi punktami (obserwacjami) w niskowymiarowej (np 2D) przestrzeni. Jest to szczególnie proste w przypadku danych geograficznych, dla których posiadamy macierz wzajemnych odległości:
Rysunek 10.6
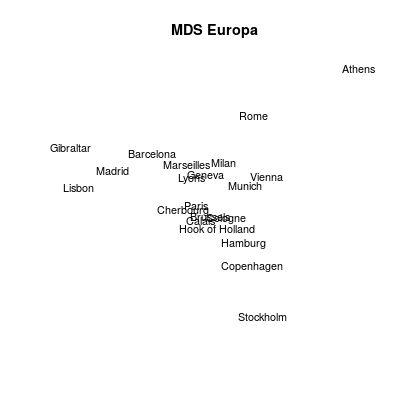
Warto jednak zwrócić uwagę na fakt, że funkcja dist() umożliwia nam wyznaczenie odległości pomiędzy zupełnie innymi typami danych (tzn. nie odegłości geograficznych), a co za tym idzie, po przekazaniu do funkcji cmdscale() również wizualizację takiegu układu.
Rysunek 10.7