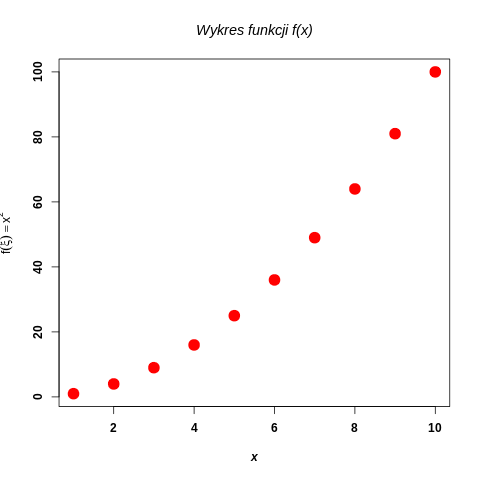
Przykład 0.40> x <- 1:10 > plot(x, x^2) 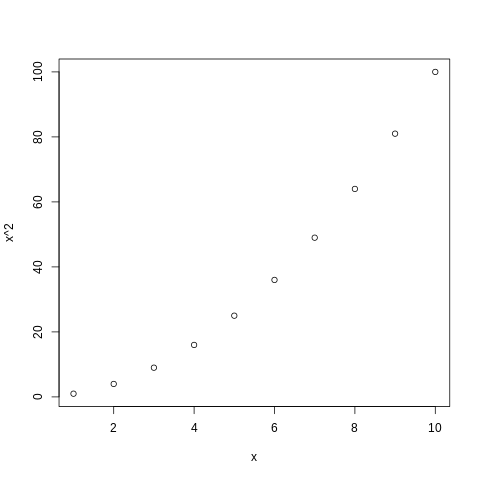
|
Statystyczna Eksploracja Danych
LABORATORIUM 0
URUCHAMIANIE I KOŃCZENIE SESJI, KOMENDY
|
INSTRUKCJA PRZYPISANIA
= <- ->
|
|
TYPY DANYCH: ATOMOWE
|
|
TYPY DANYCH: STRUKTURY DANYCH
Metody tworzenia wektorów:
|
|
TYP CZYNNIKOWY (WYLICZENIOWY, KATEGORYCZNY)
|
|
|
|
INDEKSY
Korzystając z operatorów c() (względnie c(-)) oraz : możliwe jest wypisywanie zadanych części
|
|
|
OPERACJE NA WEKTORACH I MACIERZACH
Zdefiniujmy następujące wektory w, u i macierze A, B
|
|
|
INSTRUKCJE STERUJĄCE
|
|
INSTRUKCJA WARUNKOWA IF...ELSE...
|
|
INSTRUKCJA WARUNKOWA IFELSE(WARUNEK, INSTRUKCJA1, INSTRUKCJA2)
|
FUNKCJE
Schemat tworzenia funkcji jest następujący
|
|
|
|
SKRYPTY
Skrypty w języku R uruchamiane są komendą source("nazwa_pilku"). Oczywiście, w przypadku używania własnych funkcji, należy je zdefiniować przed główną częścią skryptu, czyli po prostu na górze. W odróżnieniu od linii komend, wypisanie na ekran trzeba ubrać w odpowiednią funkcję print() lub cat().
|
|
FUNKCJE OBSŁUGI WEKTORÓW
Następujące funckcje są bardzo przydatne podczas obsługi danych w formacie wektorowym:
|
|
|
|
|
|
|
FUNKCJE OBSŁUGI MACIERZY
Część powyższych funkcji można zastosować także do macierzy, przy czym w przypadku which.min() oraz which.max() konieczne jest użycie dodatkowo funkcji arrayInd() do określenia indeksów macierzy - w przeciwnym wypadku otrzymamy tylko indeks "wektorowy".
|
|
|
|
|
|
TWORZENIE WYKRESÓW
Standardową funkcją wykorzystywaną do tworzenia wykresów jest plot(x,y), gdzie x i y są odpowiednio wektorami liczb.
|
|
|
|
TWORZENIE HISTOGRAMÓW
Najprostszą metodą tworzenia histogramu jest wykorzystanie funkcji tabulate(), przy efektem jej działania jest zliczenie wartości całkowitych zawartych w wektorze. W przypadku liczb rzeczywistych doknywane jest zaokrąglenie w dół.
|
|
|
|
LOSOWANIE WARTOŚCI
|
|
|
WCZYTYWANIE DANYCH Z PLIKU
Jedną z najczęściej wykorzystywanych funkcji do wczytywania danych z pliku jest read.table(), tworząca z wczytanego zbioru ramkę danych. Oznacza to, że w pliku każda linia powinna zawierać tyle samo pól, a poza tym każda kolumna musi zawierać ten sam typ danych.
|
|
|
|
|
ZAPISYWANIE DANYCH DO PLIKU
W przypadku macierzy oraz ramek danych odpowiednim sposobem zapisu danych jest użycie funkcji write.table(). W przypadku, gdy dane mają być "czyste" (bez nazw kolumn i wierszy), używamy opcji write.table(col.names=F, row.names=F)
|
|
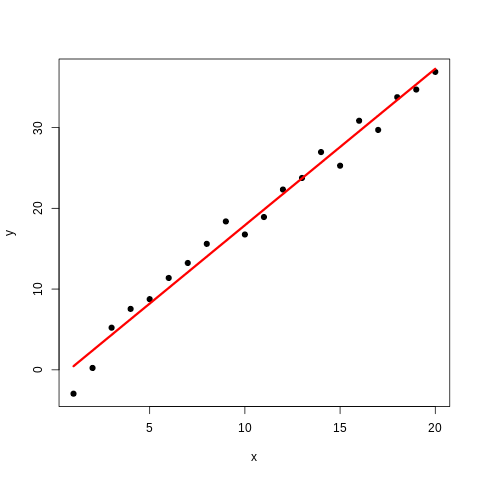
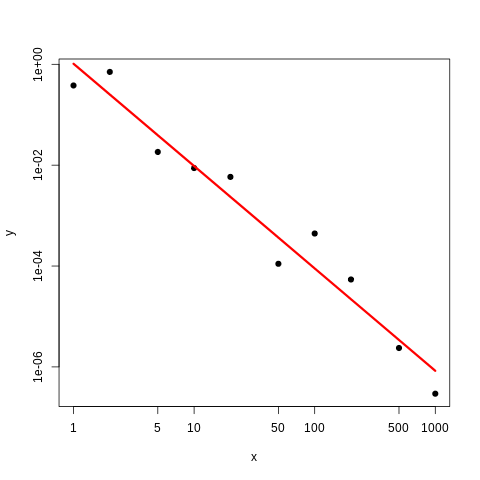
REGRESJA LINIOWA
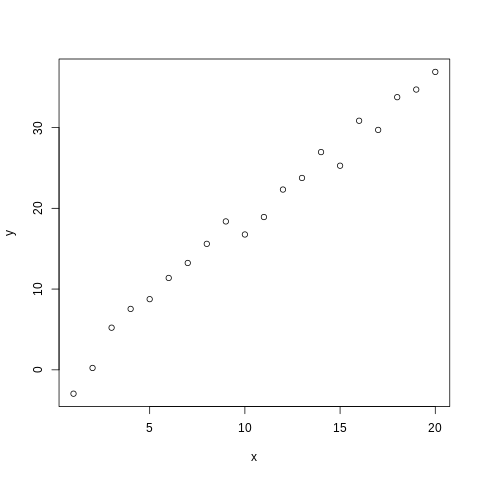
W wielu przypadkach interesuje nas wykonanie analizy regresji opracowywanych danych. W pakiecie R służy do tego funkcja lm(), przy czym specyficzny jest sposób wprowadzania formuły - w R wykorzystuje się symbol tyldy ~ do pokazania zależności pomiędzy zmiennymi (np. y ~ x oznacza zależność pomiędzy x i y. Poniżej generujemy zaburzoną losowo zależność liniową
|
|
|